浅谈趣店集团线上数据库那点事儿
站在研发工程师(RD)的视角,来看线上数据库的现状、合理的架构;同时通过常见的库表设计案例,和大家聊聊数据库的设计、优化、和运维。
一、数据库概况
1.1 关键词
- DB实例: 一个数据库服务节点: mysqld进程 / PG, Oracle主子进程
- DB集群: 具有主从复制关系的实例集合,实例级别复制
- Database: 实例的数据管理单元,一般一个实例下包含多个Database
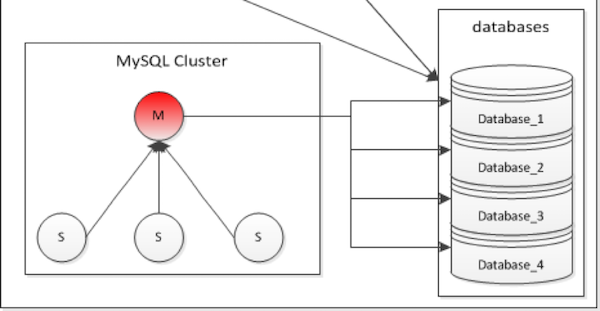
1.2 类型
- RDS(MySQL)
- 关系型数据库
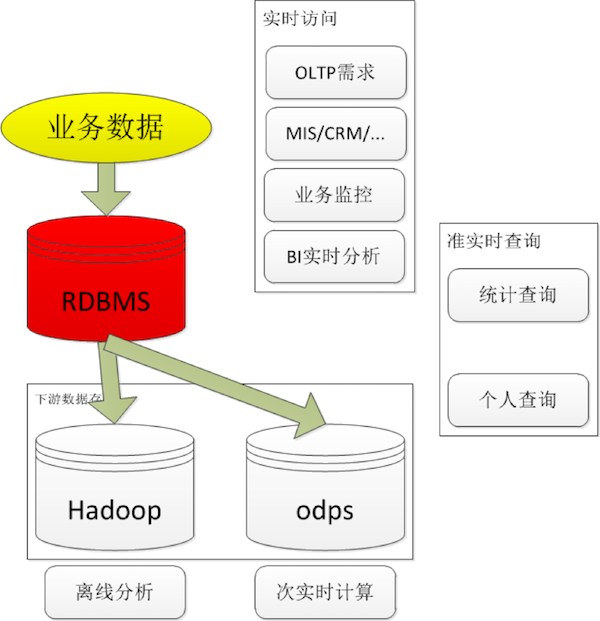
1.3 在数据生态中的位置
- 各种行为的第一手数据
- 各种分析的原始数据源
二、数据库架构
2.1 MySQL数据库服务架构
- 高可用
- 一致性
- 实例内部数据一致性
- 集群内部实例一致性
- 结构一致性
- 数据一致性
- 权限一致性
- 可靠性
- 可容灾
2.2 单点架构
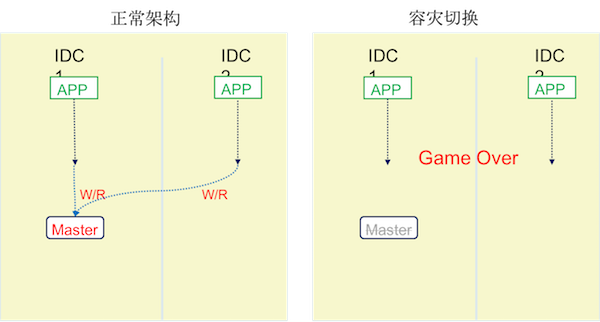
- 单点架构,不具有高可用性,甚至无法备份数据
- 单点出现故障,
导致服务不可用,甚至无法恢复!
2.3 简单主从架构
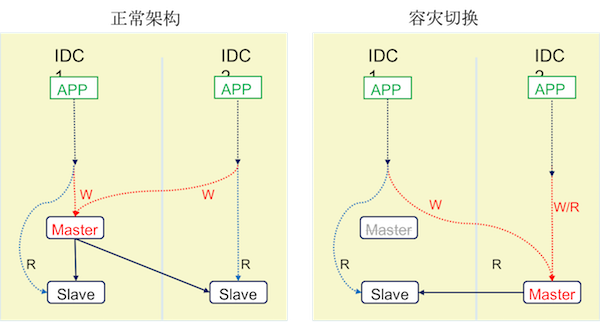
- 主从架构: 提供读写分离的可能,备份不影响服务,服务可容灾
- 故障时主库可以切换到同中心或者异地中心的从库,但
需要app进行IP/HOST更改!
2.4 二层高可用主从架构
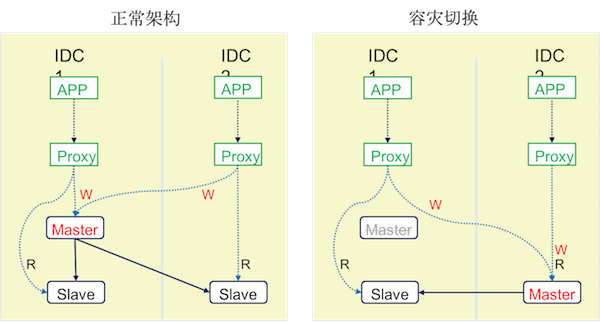
- 泛中间层架构: 从库在多IDC有相同的部署,可以横向扩展,
对业务程序透明,程序连接的IP(HOST)不变 - 故障时主库可以切换到同中心或者异地中心的从库,
对业务程序透明
2.5 DNS+主从架构(次二层)
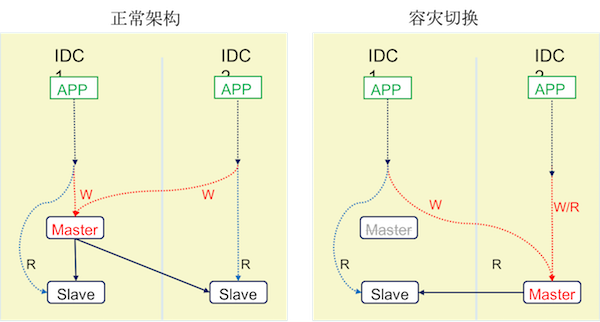
- 泛中间层架构: 从库在多IDC有相同的部署,可以横向扩展,
对业务程序透明,程序连接的HOST(域名)不变 - 故障时主库可以切换到同中心或者异地中心的从库,
对业务程序透明
2.6 三层高可用主从架构
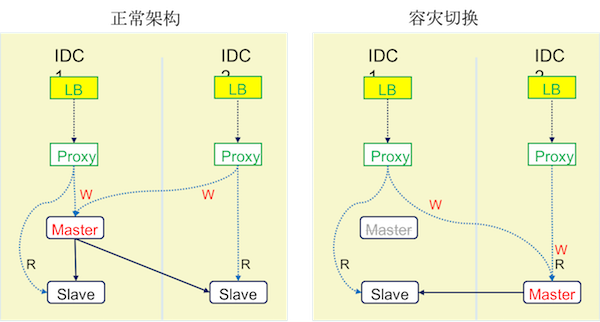
- 3层数据库架构: 引入
接入层,提供中间层的高可用,并且接入层本身实现高可用 - 本质上
总需要有一层实现本身的高可用,否则还需要应用程序实现 - 原则上,应用程序还是
需要具备对下游服务访问的冗余、重试机制
2.7 RDS架构
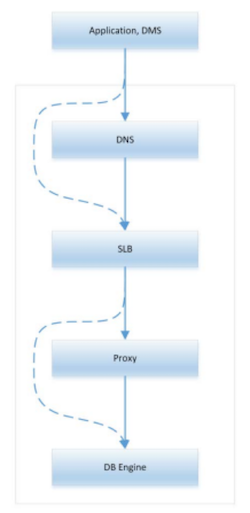
- 本质上是小三层架构
DNS + SLB + (dbproxy+) MySQL (RDS)- DNS: 屏蔽IP变化的影响
- SLB: 屏蔽proxy/MySQL变化的影响
- Dbproxy: MySQL协议层的代理
- 屏蔽MySQL层拓扑变更的影响。
- MySQL:集群
- 主从集群
- 顶点带环的集群
2.8 中间件分布式架构
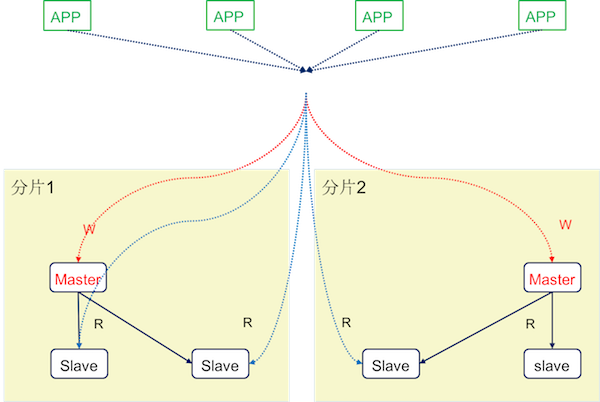
2.9 MySQL架构演化
- 单集群架构
- 单点架构 ==> 主从架构 ==> 高可用架构
- 基于MySQL中间件的分布式数据库
- 本质就是
分库、分表 - 是对 应用端分库、分表需求的抽象后的产品
不支持分布式事务只支持简单的分布式JOIN(JOIN的数据在同一分片上)
- 本质就是
- NewSQL: 真正的分布式事务数据库
- 支持分布式事务、分布式JOIN
Just like a single RDBMS
三、数据库设计
3.1 流程、标准化与安全意识
- 上线前一定要
确认、确认、再确认- 推广jira流程,部分业务线已试用
- 增强安全意识
- 原则上,上线需求,
DBA只对接RD/技术人员
- SQL脚本附件/ UTF8编码
- 保证
需求与执行的一致性
- 保证
- 流程与标准
- 降低沟通成本及出错概率
- 流程(通过wiki沉淀、宣讲贯彻执行)
- 其它流程、规范、操作标准 补充中
3.2 评审流程建立
先评审,后上线- 库、表
- 结构设计
- 读、写流量
- 数据量
- 行数
- 行长
- 增长趋势
- SQL流量
- SQL是否规范
- 天流量
- 秒高峰
- 流量趋势
3.3 应用架构
- 推荐的架构
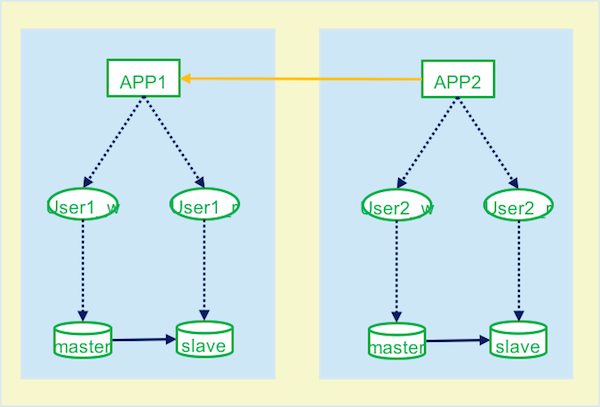
- 不推荐的架构
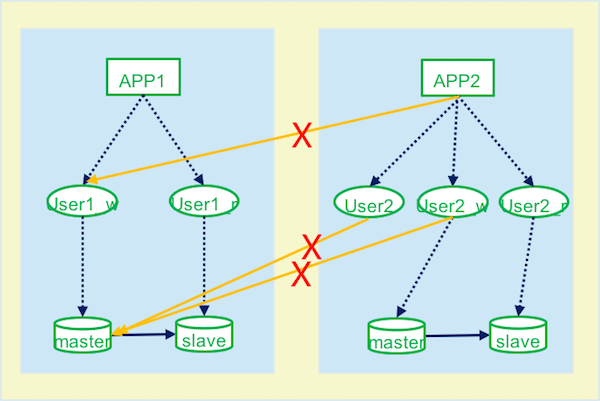
说明:
使用简单化: DB退化为持久化存储,不再支持复杂算法运算和业务逻辑运算访问接口化: DB降格到应用程序作用域内部,不对外直接暴露数据,仅允许通过应用程序接口访问,以降低程序间的耦合
3.4 大库设计与拆分
- 产品线所有的表(上百张)在一个库中
- 垂直拆库(按业务类型拆分)
<=========>微服务拆分
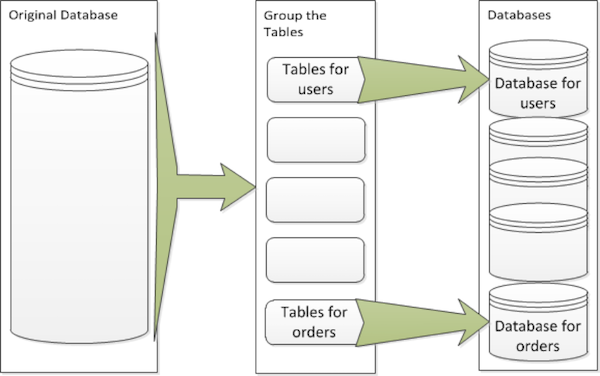
3.5 大数据表设计
3.5.1 常见情况
- 行数多
- 影响DML效率,尤其是统计查询。
- 字段多
- 导致行较长
- 行太长 (KB级别)
增加磁盘IO消耗
- 表文件大
磁盘空间紧张- 后续维护成本高
3.5.2 应对策略
- 归档
- 设计时提前考虑清理方案
- Sharding
- 业务应用程序层做table sharding
- 使用方也需要走sharding的路由
- 基于MySQL的分布式数据库中间件做table sharding
- 不支持分布式事务
- 跨分片JOIN有限制
- 不会这样用,也不会希望这样实现
- 单独建立索引表
- 业务应用程序层做table sharding
- 垂直拆表
- 单表拆多表
- 字段合并 + 大字段拆分
- 单独存储到独立的库中
3.6 大字段设计
- 行长消耗IO
- 行长不可控 (text/blob系)
- 影响查询效率
- 空间增长快速
单独建表存储大字段使用其它存储系统持久化大字段内容
3.7 一般字段设计
- 类型设置
- id / BIGINT / not null / auto_increment / primary key
- 后期改动成本大: 应用程序类型转换 / RDS不支持平滑变更
- No enum / 使用tinyint / smallint / code
- 一些数据需要公司级别的统一定义: 元信息/元元信息
- id / BIGINT / not null / auto_increment / primary key
- 属性设置
- 一些使用规范设置
- NOT NULL/ DEFAULT/ COMMENT
- 初始化表: AUTO_INCREMENT的设置
- 一些不要自行设置
- Charset, Collation, 表引擎 等等使用默认配置即可
- 一些使用规范设置
3.8 SQL设计
- 业务SQL均应为小SQL
- 关键操作: 大SQL应拆分为小SQL
Do Not!- SELECT *
- INSERT不显式地指定字段
- 大表、多表JOIN
- 数学运算、逻辑判断
- 线上业务含统计查询
3.9 数据消费问题
- 跨库查询
- CASEs: 来分期数据库集群上的laifenqi + from_shop
- 表同步、业务库负载增加、与业务库跨库查询
- 复杂统计
- 实时分析: 低复杂度SQL 分钟级定时查询,耗时<5秒级
- 统计分析: 高复杂度SQL 天级别定时查询,耗时 >=10分钟级
- 问题
- 库内业务独立原则
- 日志表单独存储 / 迁移存储
- SQL执行资源限制
- 一个SQL最多在一个DB实例上执行
- 一个SQL的执行是单线程的
- 库内业务独立原则
- 优化
- 资源隔离
- 数据应用架构
- 存储方式调整
- 数据应用逻辑
- SQL拆分 / 访问逻辑调整
3.10 数据库设计之大道至简
- 逻辑库独立
- innodb + UTF8,表数据量小,数据短
- 类型简单: 整型系、varchar、时间、浮点定点数
- 索引: 区分度高、复用度高、字段短、不多
- SQL: 化整为零,尽量使用小SQL,简单SQL
- 朴素的使用方式,最可靠
- 需求、架构、逻辑 的优化 –> SQL优化
四、数据库运维
4.1 架构
- RDS解决了什么?
- 主库高可用
- 单个只读实例高可用
- 还有什么RDS无法解决?
- 延迟问题的处理
- 大表的平滑操作
- 授权灵活性问题
- 不开放部分接口
- 同步信息
- 配置信息
- 数据文件/目录: 准确信息无法拿到
4.2 监控
- RDS解决了什么?
- 常用监控数据
- 常见日志采集
- 还有什么RDS无法解决?
- 定制化监控数据的采集
- 需要更详细的监控数据
- 数据库日志的多维度分析
- 需要面向应用与运维进行分析、感知
- 监控粒度与频率自定义
- 更细粒度的监控
- 更高频率的采集
- 定制化监控数据的采集
4.3 DB灾备体系
- CASEs
- 炉石 / GitLab / …
- 容灾的2个方面
- 数据容灾
- 物理容灾: 如果线上集群实例遭遇物理损坏,数据资产如何恢复?
- 基于复制机制 < == > 服务容灾
- 逻辑容灾: 如果因误操作导致数据逻辑错误,数据资产如何恢复?
- 基于备份恢复 < == > 如何准确、快速地回滚数据并保证一致性?
- 物理容灾: 如果线上集群实例遭遇物理损坏,数据资产如何恢复?
- 服务容灾
- 单点容灾: 主从复制 + 高可用机制
- 集群容灾: 集群间同步 + 高可用机制
- 异地容灾: 集群容灾
- 数据容灾
- 逻辑误操作恢复
- DDL: DROP/TRUNCATE
- Oracle: 回收站
- MySQL: NO
- DML: delete/update/…
- Oracle:
- UNDO
- BACKUP + REDO
- MySQL:
- BACKUP + BINLOG/REDO
- 这是做延迟备份的困难之处
- BACKUP + BINLOG/REDO
- Oracle:
- DDL: DROP/TRUNCATE
4.4 操作方案
- DROP/TRUNCATE
- ALTER TABLE
- 批量操作(delete/update)
- 先select,后根据主键,间歇式的循环 delete/update
- 灌数据
- 串行灌数据
- 一些场景需要sleep
- 数据迁移
- RDS == > ECS - MySQL 不严重依赖于阿里云
- 基于分布式架构的各类操作方案
4.5 自动化
- 面向应用 (自动化 == > 自助化)
- 上线
- 审核
- 导出
- 面向运维 (自动化、半自动化、工具化)
- 各类日常操作
- 集群拓扑变更、授权、切换 等等
- 低风险操作方案
- 归档/清理、DDL 等等
- 基于分布式架构的各类操作方案
- 各类日常操作
